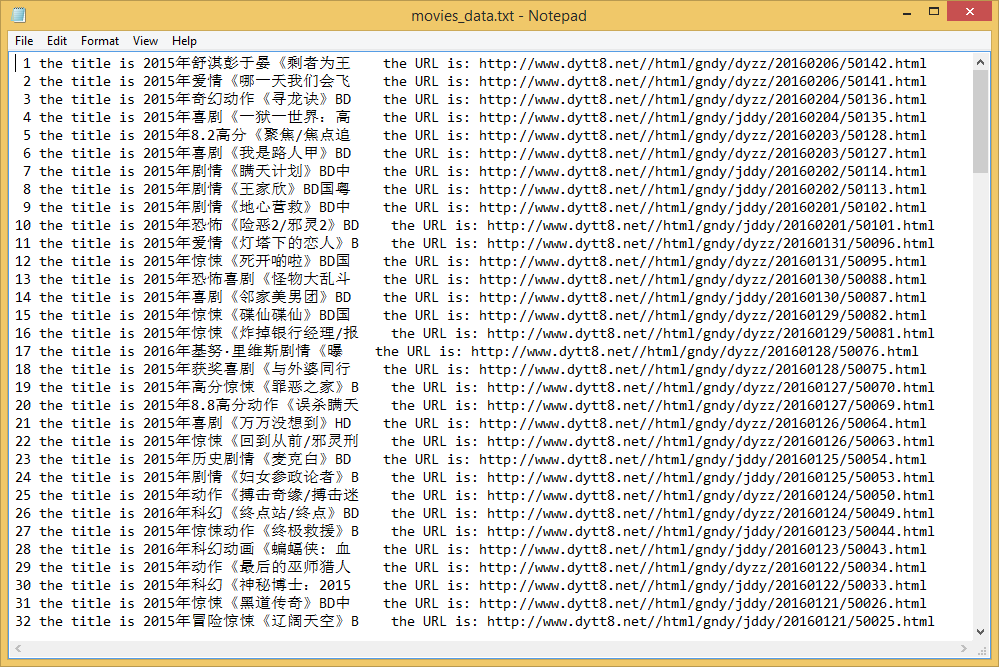
3.5 爬虫程序(二)——爬电影天堂170部最新发布电影名称及链接
参照仿写的程序,主要是为了熟练scrapy和xpath的使用。
爬取电影天堂(http://www.dytt8.net/)的最新发布170部影视
查看源代码,我们可以看到其结构还是比较简单,易于小白学习。
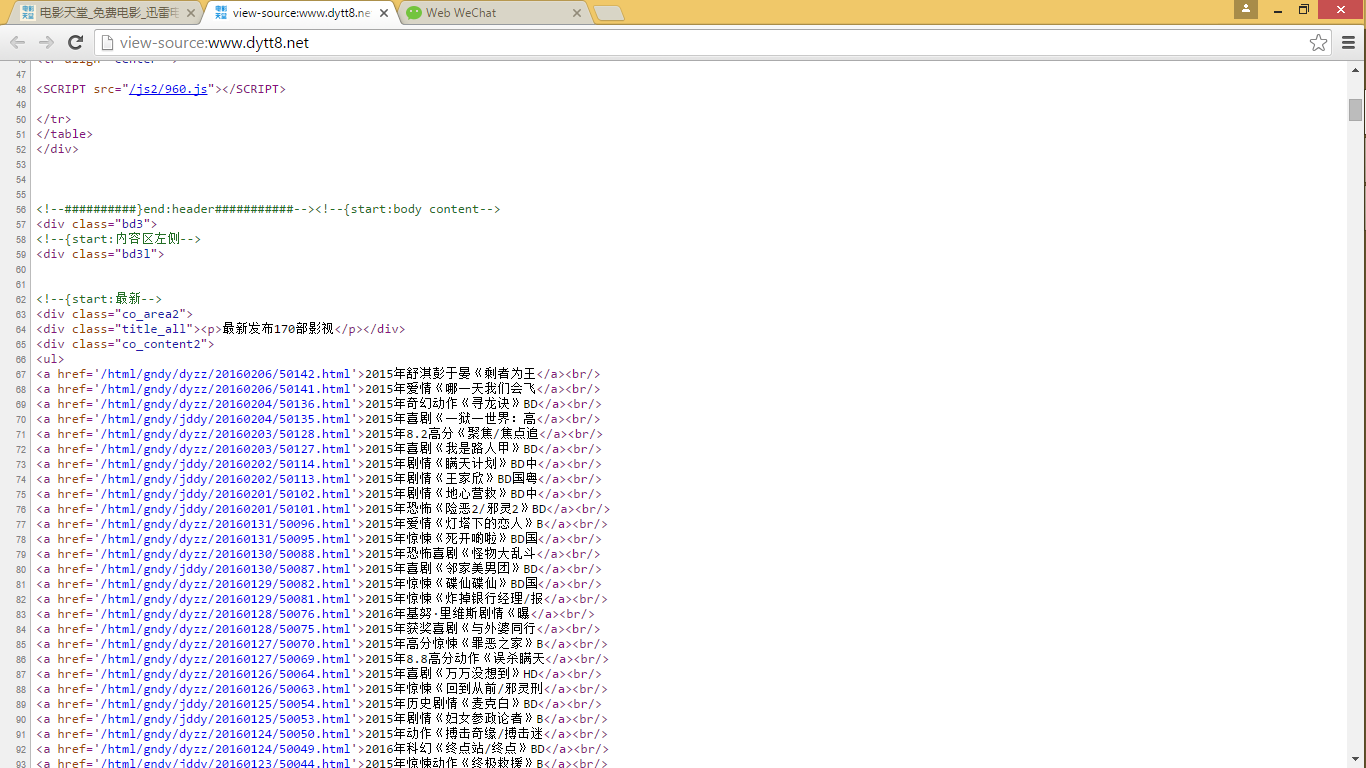
正文:
创建工程
scrapy startproject Dytt
1.编写Item.py
- 抓取对象选择为链接和电影的名字
import scrapy
class DyttItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link = scrapy.Field()
dyName = scrapy.Field()
2.编写pipeline.py
import json
import codecs
class DyttPipeline(object):
def __init__(self):
self.file = codecs.open('movies_data.json', mode='wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_close(self,spider):
self.file.close()
3.编写setting.py
BOT_NAME = 'dytt'
SPIDER_MODULES = ['dytt.spiders']
NEWSPIDER_MODULE = 'dytt.spiders'
COOKIES_ENABLED = False
ITEM_PIPELINES = {
'Dytt.pipelines.DyttPipeline':300
}
4.编写spider
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Dytt.items import DyttItem
class dyttSpider(Spider):
name = "dytt"
allowed_domains = ["dytt8.net"]
start_urls = ["http://www.dytt8.net"]
def parse(self,response):
sel = Selector(response)
item = DyttItem()
dyurl=sel.xpath('//div[@class="co_content2"]').xpath('.//a[contains(@href,"gndy")]/@href').extract()
dynaming=response.xpath('//div[@class="co_content2"]').xpath('.//a[contains(@href,"gndy")]/text()').extract()
item['link'] = [n.encode('utf-8') for n in dyurl]
item['dyName'] = [n.encode('utf-8') for n in dynaming]
return item
【1】 如何使用xpath从网站中提取想要的信息
【2】转换编码UTF-8
运行
scrapy crawl dytt
得到movies_data.json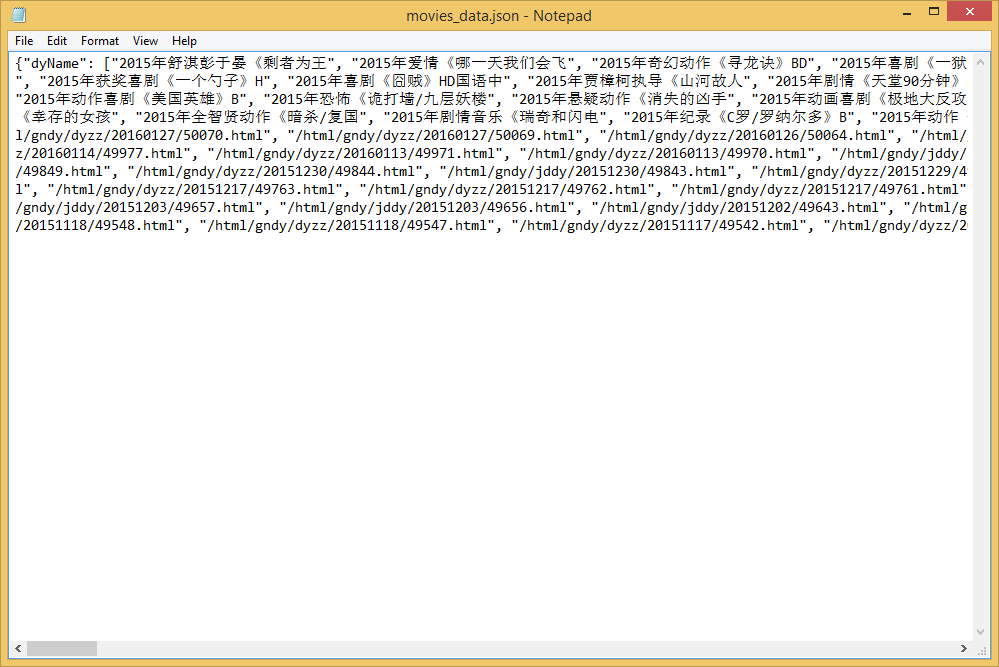 json文件转换为TXT文本
json文件转换为TXT文本
import json
data = []
with open('movies_data.json') as f:
for line in f:
data.append(json.loads(line))
import codecs
file_object = codecs.open('movies_data.txt', 'w' ,"utf-8")
str = "\r\n"
1
for item in data:
for n in range(len(item['link'])):
str = "%2d the title is %s the URL is: http://www.dytt8.net/%s\r\n" % (n+1,item['dyName'][n],item['link'][n])
file_object.write(str)
file_object.close()
print "success"
【1】open路径要设置对
【2】要知道获得的item的类型
运行后输出txt文本: